Lambdas for extreme cheapskates
Intro
Its longs time since my last tech post. In this post I want to share my experience with AWS Lambdas and particularly how to work with them not paying much. One of my jobs is related to startups and as it often happens startup runs out of money and when it happens I have to pay for infrastructure out of my wallet. This situation makes me very motivated to “squeeze the juice out of a rock” and get as much as possible from AWS Lambdas paying as little as possible.
9x suggestions how to run Lambdas as cheap as possible.
1 - Know how much you use and pay.
First most important thing is to understand how much you are paying.
There are many ways one is to tag your infrastructure and see how much infra. with particular tag assigned costs. This approach can be imprecise as there can bet parts of infrastructure commonly shared but when different projects (for example Internet Gateway that allows internet access from your VPC ).
Another approach is to operate in “clean” AWS account where you have only one project.
No matter what approach you choose you can use “My Billing Dashboard” to see details of usage (how many minutes / GB / etc. ) you have used per month and how much it costs.
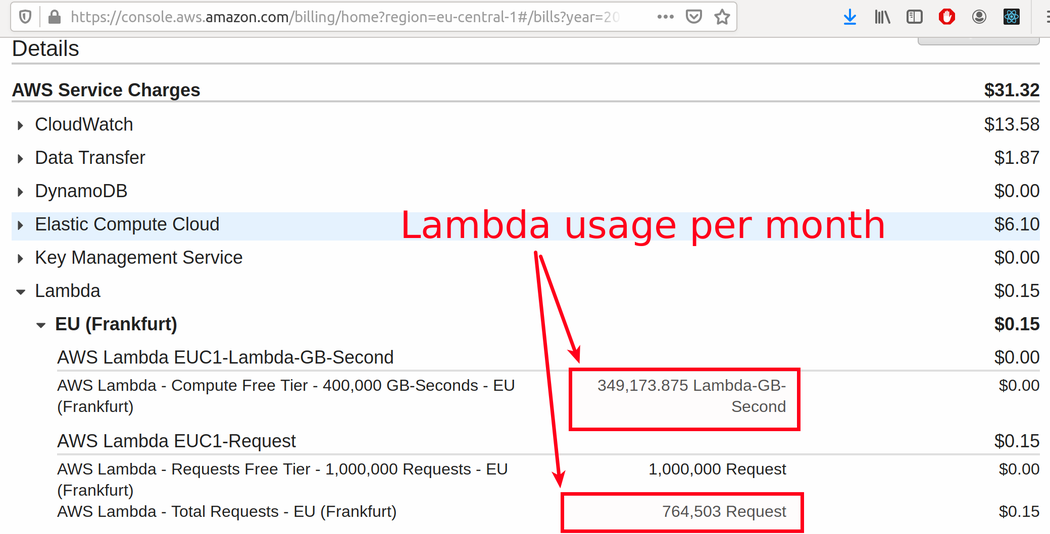
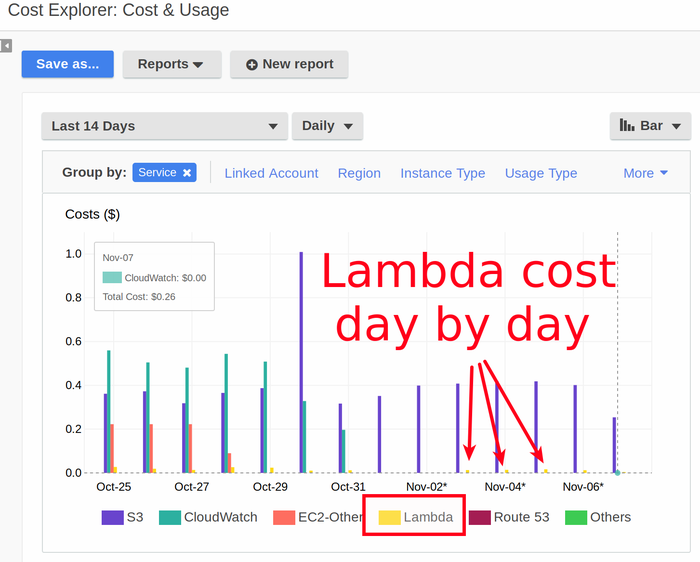
and also “Cost explorer” - will show you cost per service per day
2 - Know Lambda cost “theory”.
According to pricing cost reflects usage . For example you can assign 254 MB to Lambda function and run it 10 s. on each request and have 100 k requests during month in this case you will pay :
Total execution time (seconds) = 100 000 * 10 (s) = 1 000 000 seconds
Total compute time (GB-s) = 254 MB/1024 * 1 000 000 = 248046.87 GB-s
Total compute cost ( $ / EU -Frankfurt ) = 0.000000417 (1 s) * 248046.87 = 0.1034355 usd
Total request count ($0.20 per 1 million requests) = 0.2/1 000 000 * 100 000 = 0.02 usd
Total cost = 0.1034355+ 0.02 = 12 cents !
Takeaway we need to optimize three things :
- Lambda function size (less MB, less CPU).
- Number of request (less requests).
- Time lambda need process one request.
We dont consider costs of data transfer also we dont take to account discount of AWS free tier.
3 - Remove unneeded infrastructure.
There are two ways to deploy Lambda function. One is attached to VPC and other without VPC attachment (public). In case your functions needs to be hidden in VPC and accessed by other VPC resources (instance/ db / queues etc) there are lot of stuff that is powering VPC and cannot be removed. In option two (no VPC attached) you can search for parts of infra that are left from VPC deployments are not used anymore and can be removed.
One of things I discovered early was AWS “NatGateway” that was used to access internet from private subnets to public subnets. By removing “NatGateway” I saved some amount of money.
4 - Review your code.
Next thing I did was to look on my code. My Lambda was write in java so some things to consider reviewing code :
-
Investigate dependencies and remove unused => less jar size less function memory required.
-
Think how exception are thrown and cached, you want to fail (finish) you function execution as fast as possible. For example, if function works with queue you want to throw exception once there is network error or queue is empty and exit function execution. => less function run time less you pay.
-
Consider when you open connections. For example, if you need to take task from queue and put results in db it makes sense to :
1) Open connection to queue 2) Get task from queue 3) Close connection to queue 4) Process task 5) Open connection to db 6) Write results to db 7) Close connection to db
This way if function throws exception in any step there is less connections to close and exit function. Also you have spend less time opening connections because max open connections ==1 .
-
Write Lambda function to perform only one thing. Dont create “lambda monolyt” functions they will be heavy and slow. You want your function to do one thing and fast.
-
Avoid multi thread tasks. As you may know lambda function can have “cold start” (starting first time) and “warm start” (starting after pause ) its hard to ensure all threads are finished executing before code on system is suspended. Also avoid fancy connection polls (with thread safe) because you dont need it, keep it simple.
5 - Avoid debug logs.
As you may know all output stdout from functions are stored in AWS CloudWatch its very useful to debug functions. It can sound strange but some times (most in my case) cost for storing logs are higher than execution of function itself! According to CloudWatch pricing you pay for sending logs to CloudWatch and for storing logs. A simple calculation is 0.63 usd / 1 GB you send to logs.
So the suggestion is :
-
First avoid sending debug logs, never deploy to prod with debug logger turned on for long time. Make your logs meaningful (log
errorsandwarnings) keep minimum ofinfologs. -
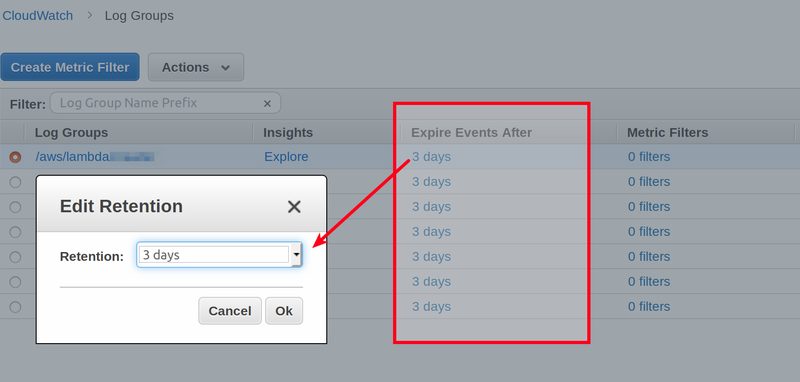
Set log retention period, smaller retention (less days) less you pay for CloudWatch. Be realistic if you are investigating bug usually 1-3 days of logs are enough.
-
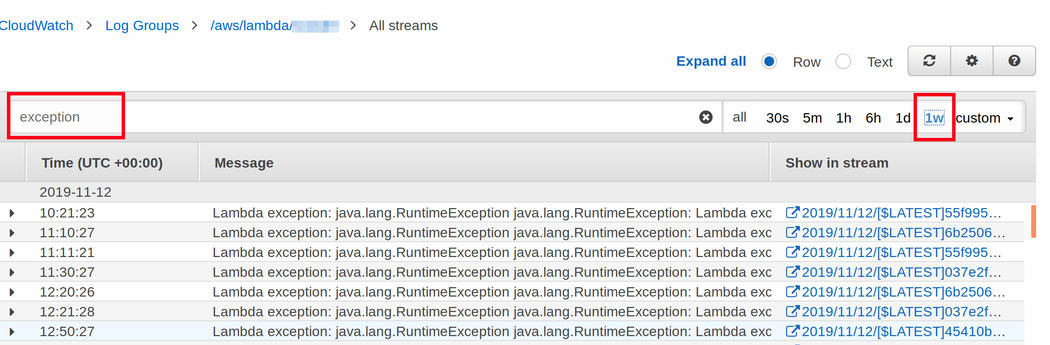
Dont use AWS Logs Insights ! Its uber expensive stuff, you pay for each query and amount of data query needs to analyze (0.0063 usd per GB of data scanned). Instead you can use “Search Log Group” functions just select “Log Gropu” enter search criteria (for example : “exception”) and search period.
6 - Adjust function memory.
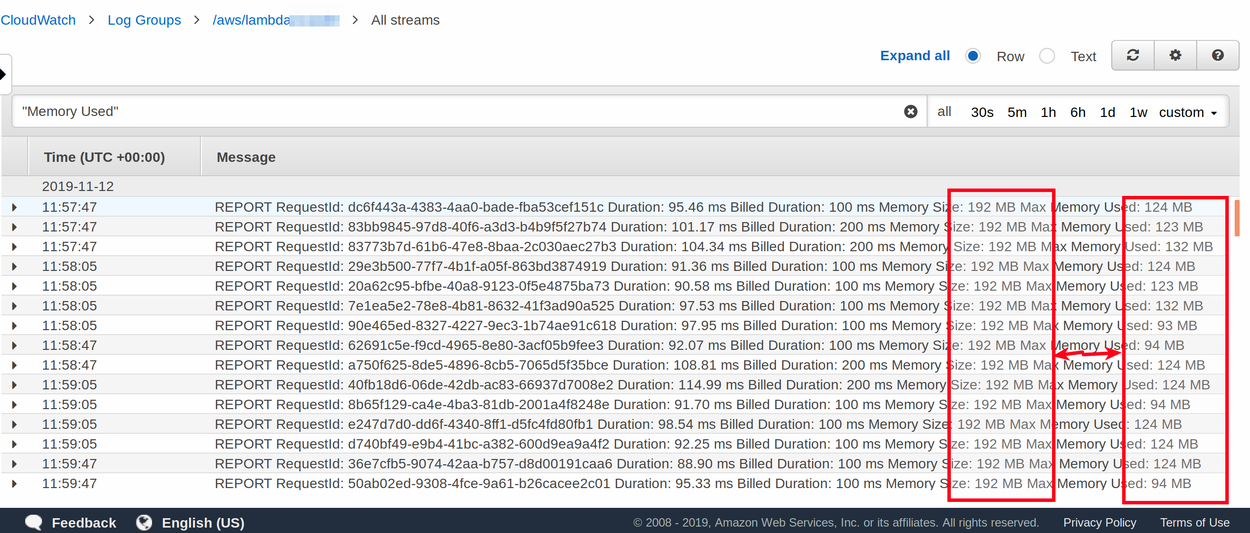
This suggestion can sound obvious but after each improvement, it makes sense to see maybe we can decrease reserved memory. So simplest way to do it is search Log Group by “Memory Used“ if used memory is below 64 MB (min. step to increase decrease mem.) of assigned memory “Memory Size” this is clear sign we can decrease reserved memory and save money. Please remember JVM memory usage is hard to predict it can spike depending on how heavy jobs is.
7 - Look for memory leaks
In JVM world usually we dont care much about memory usage because its simpler to buy bigger EC2 instance or restart app if it crash than debug memory usage inside JVM. With serverless its different if we can eliminate memory leaks we can save money on every invocation. So nothing new just set up JVM profiler ( I prefer yourkit but you can use any other ) and profile your app. Will not describe how to do profiling there is enough articles on it.
One interesting aspect → JVM memory consists of Heap memory (contains of class instances, arrays, etc.) and Non-Heap memory (contains of runtime constant pool, fields, method data, etc.) its not clear how AWS Lambda start JVM but general assumption is 85% of lambda memory is assigned to JVM. But its not clear how memory is distributed between Heap memory and Non-Heap.
In my experience I have seen cases when Lambda gives error java.lang.OutOfMemoryError: Java heap space but execution report says something like “Memory Size: 192 MB Max Memory Used: 123 MB ” so my point is :
-
You can not relay on CloudWatch log output as it is showing some aggregated memory usage value (see example above).
-
Its not possible to know (or I dont know) which memory is over used.
BTW Its easy to check function JVM memory : for example if we set Lambda memory size “256 MB” and in code print max memory Runtime.getRuntime().maxMemory() we will see JVM is assigned “~220 MB” (86% :D).
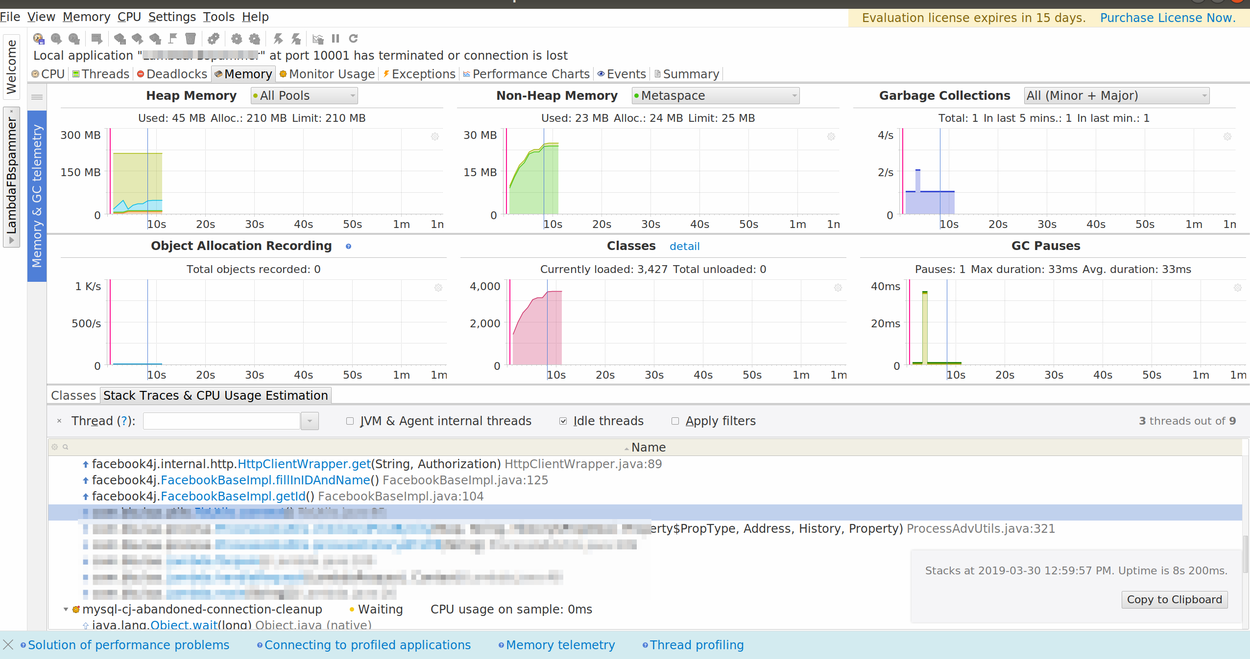
In my functions example (executed on local machine with -Xmx = 256) you can see usage on heap is small but non-heap very high so my assumption is that I will get java.lang.OutOfMemoryError for non-heap.
8 - Optimize for MEM or CPU
As mentioned before in AWS Lambda you pay for usage (function size mb * execution time). Most of time we want to use less memory but there are cases when our function is demanding lot of cpu and less memory. In these cases it makes sense to increase function memory size to get more cpu and execute function faster (lest execution time). But it depends on what functions is doing.
9 - Think about how you execute function.
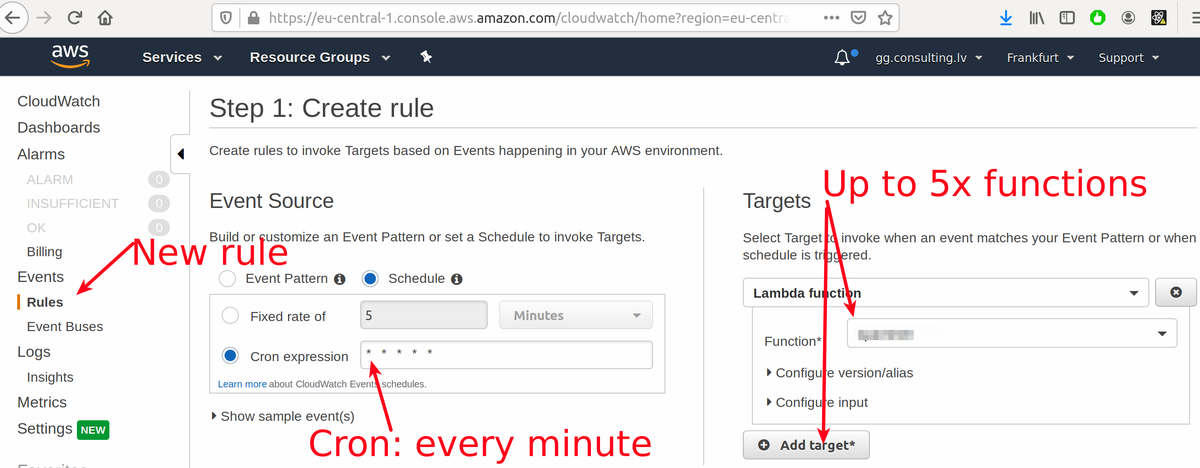
Best practice says we need to bind our function to some event. Event can be state change in queue, change in db, trigger of REST api, etc. But not always its possible to assign function to event, I have seen cases when functions is triggered by cron job or other app. One thing I learned is any out side invocation with authentication is super slow (because every call needs to be authenticated). So for example loop in bash script with aws lambda invoke ... will boil your server and there is no way you can invoke 10 lambdas in parallel. One solution I found was AWS rules they allow to invoke up to 5x functions per minute per one rule. For small loads it can be enough.
Conclusion
Lambdas is great way how to start fast hook up function with “API Gateway” or SNS write java code without Spring and dont care about threads. Unfortunately, if you want to be cost effective and/ or serve high load you will spend lot of time digging and understanding lambda specifics. Even when you will reach “nirvana” with your Lambda code there are other parts of infrastructure (database / LB / proxys / etc. ) that can become bottleneck, so the way of ~summary~ devops is to constant monitor/ investigate and improve.
BTW at moment, I am open for contract work if you need help with Lambdas / cloud native stack / devops in general.